
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Gradient Boosting Machine
- Back-propagation
- lime
- deep learning
- Gradient Tree Boosting
- Explainable AI
- XGBoost
- Machine Learning
- data science
- Today
- Total
Kicarussays
[Transformer 이해하기 1] Sequence-to-Sequence, seq2seq 설명 및 코드리뷰 본문
[Transformer 이해하기 1] Sequence-to-Sequence, seq2seq 설명 및 코드리뷰
Kicarus 2022. 1. 20. 22:14Transformer를 소개한 논문인 Attention is all you need를 읽으려고 보니..
encoder, decoder 조차 모르는 상태였습니다..
seq2seq 논문 링크:
https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf
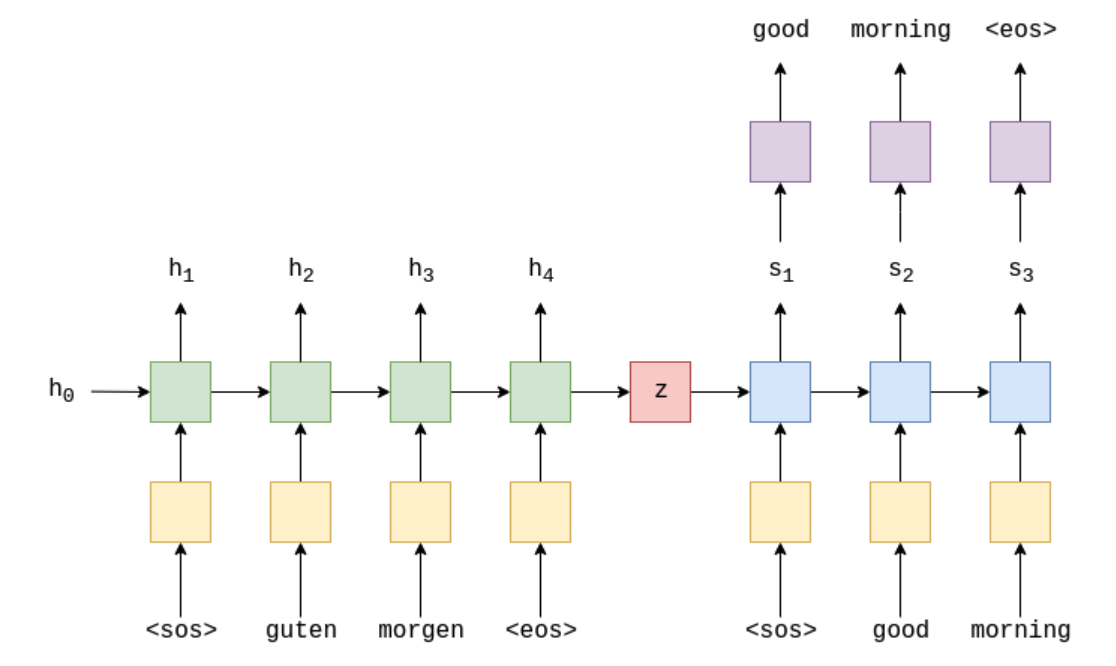
아래 이미지는 Encoder-Decoder 예시를 아주 잘 보여주는 이미지입니다. Encoder에서 input 문장을 z로 임베딩하고, z를 Decoder에서 target 문장으로 출력하는 과정인데, Pytorch로 구현된 코드를 따라가보겠습니다!
GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and Torc
Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and TorchText. - GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2se...
github.com
Introduction
위 이미지는 독일어 "guten morgen" 을 영어 "good morning" 으로 번역하는 예시입니다. (좋은 아침 !)
input은 문장의 시작을 나타내는 sos (start of sentence), 문장, 문장의 끝을 나타내는 eos (end of sentence)로 구성되어 있습니다.
input은 딥러닝 모델에 들어가기 위한 형태로 "embedding" 됩니다. "guten"이라는 단어가 one-hot encoding 등의 과정을 거쳐서 모델에 진입할 수 있는 형태의 벡터 등으로 변환된다는 뜻입니다.
먼저 Encoder를 표현한 식을 살펴봅시다.
$$h_t = \text{EncoderRNN} (e(x_t), h_{t-1})$$
Sequence 형태의 데이터를 처리하는 데 유용한 RNN (e.g. LSTM, GRU...) 을 인코더로 사용하게 됩니다. 여기서 $e$는 임베딩 함수로, input 문장을 적절한 형태의 벡터로 변환해주는 함수입니다. 위의 예시에서는 $x_2$은 guten, $e(x_2)$은 변환된 벡터가 되는 것입니다. $h_0$는 사전에 initialize 되거나 0의 값을 갖습니다.
이제 Decoder를 살펴봅시다.
$$s_t = \text{DecoderRNN} (d(y_t), s_{t-1})$$
마찬가지로 RNN을 사용합니다. 여기서 $d$는 마찬가지로 output 문장을 변환하는 임베딩 함수입니다. $y_2$는 good이 되겠죠. $s_0$는 Encoder에서 마지막 부분에 산출된 hidden layer 값인 $h_T$를 사용합니다. (위의 예시에서는 $h_4$, $s_0 = z = h_4$)
이제 코드를 살펴봅시다!
Preparing Data
Goal. 독일어 -> 영어 번역 모델
필요한 패키지를 불러옵니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spaCy 패키지는 자연어 처리에 도움을 주는 패키지입니다. 여기서는 문장 데이터를 토큰화 (tokenization) 하는데 사용할 것입니다. 토큰화는 "Good morning!" 같은 문장을 ["Good", "morning", "!"] 처럼 변환해주는 것입니다.
이어서 터미널에서 아래 코드를 통해 토큰화 모델을 다운받아주고,
(en_core_seb_sm: 영어 토큰화 전용 모델, de_core_news_sm: 독일어 토큰화 전용 모델)
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
파이썬으로 돌아와서 토큰화 모델을 불러옵니다.
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
이제 토큰화 함수를 만드는데, input 문장의 토큰화 이후에 순서를 뒤집는 작업이 추가되어 있습니다. ( [::-1] 부분 )
논문에서는 input 문장의 순서를 뒤집었을 때, 더 좋은 성능을 보였다고 말합니다. 자세한 이유는 설명되어 있지 않네요.
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings (tokens) and reverses it
"""
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
이제 토큰화된 문장을 파이토치 텐서로 받아주는 Field 함수를 정의합니다. 독일어 -> 영어 번역 모델이니, 독일어를 source(SRC)로, 영어를 target(TRG)로 지정합니다.
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
학습 데이터를 불러오고, 각 데이터의 사이즈와 example을 살펴봅니다. src에는 독일어가, trg에는 영어가 토큰화되어있는 것을 확인할 수 있습니다. src에서 리스트의 처음에 '.'이 있는 것을 보니 독일어의 토큰화 이후에 순서가 뒤집어진 것을 확인할 수 있습니다.
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
print(vars(train_data.examples[0]))
이어서 단어들을 벡터에 정수로 부여하기 위한 vocabulary를 만들어줍니다.
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")
만든 vocabulary로 데이터셋을 숫자 벡터로 매핑해줍니다. 이 때 BucketIterator 함수를 활용하게 되는데, 파이토치의 Dataset, DataLoader와 비슷한 역할을 수행하는 것 같네요. 자연어 처리에서 일괄적으로 데이터를 매핑하는 함수입니다.
아래 코드에서는 먼저 train 데이터의 예시를 살펴보기 위해서 device 부분에 gpu를 할당하지 않고, 예시를 print해서 살펴본 후 다시 device에 gpu를 할당하였습니다.
(device에 gpu를 할당하면 바로 print되지 않습니다)
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE)
print(next(iter(train_iterator)).src)
print(next(iter(train_iterator)).src.shape)
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
* 이 코드에서 batch size는 128로 설정하였습니다.
* BucketIterator는 미니배치 안의 문장들을 모두 같은 길이로 맞춰주는 기능이 있습니다.
* 위의 print에서 행렬 마지막 부분이 모두 1로 되어 있는데, 문장의 길이를 미니배치 안에서 가장 긴 문장과 맞춰준 것입니다.
Building the Seq2Seq Model
2개의 LSTM layer를 가진 Encoder 부분을 다음과 같이 모식화할 수 있습니다.
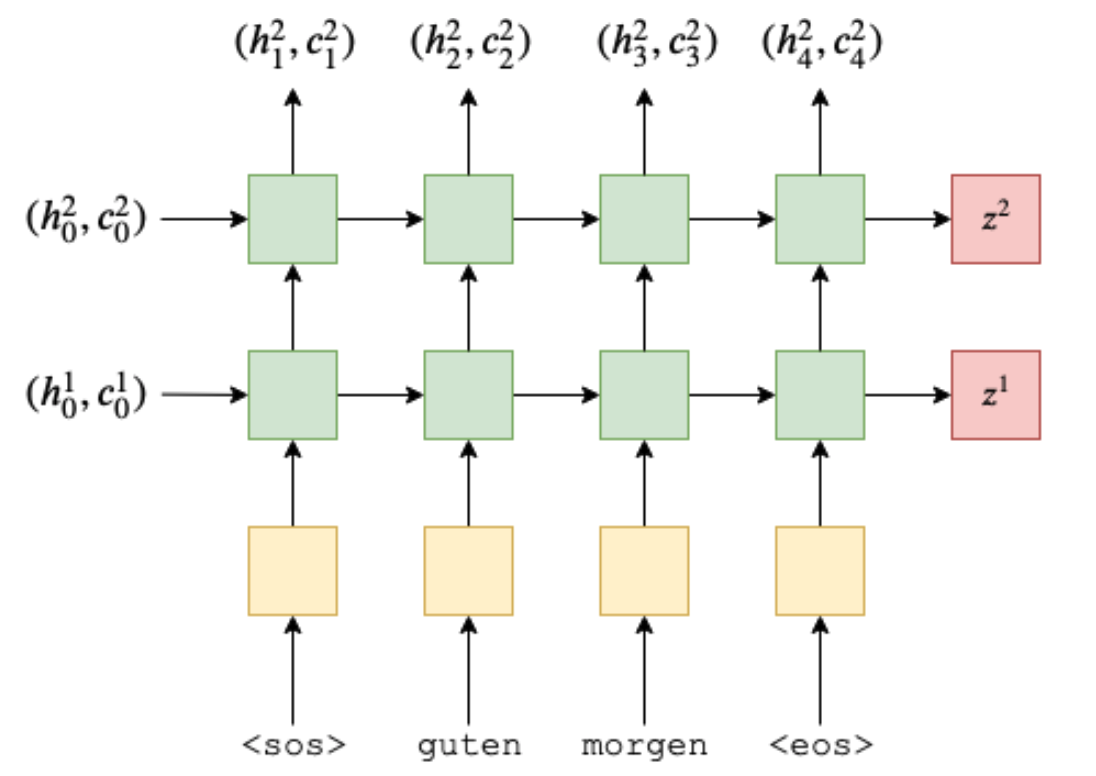
여기서 $z^1 = (h_{4}^{1}, c_{4}^{1}), z^2 = (h_{4}^{2}, c_{4}^{2})$ 입니다.
Encoder를 구현한 코드는 아래와 같습니다.
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
* 이 코드에서 hidden, cell 부분만 리턴하는데, 이 hidden, cell을 Decoder의 input으로 사용하기 위해서입니다.
* 코드에서 n directions 라고 적힌 부분은, 단방향 LSTM의 경우 1, 양방향일 경우 2의 값을 갖습니다.
* 단/양방향에 대한 설명은 생략합니다. 본 포스팅은 단방향을 가정합니다.
Decoder는 아래와 같이 모식화할 수 있습니다.
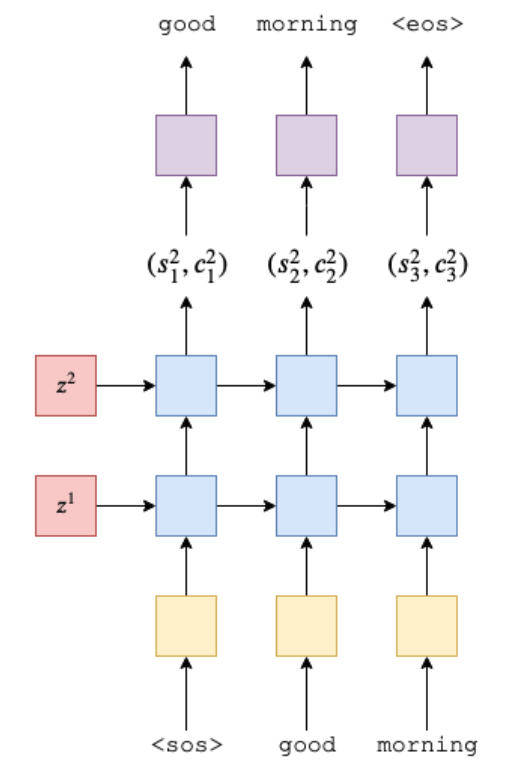
Decoder의 코드를 살펴봅시다.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
* 첫 번째 step의 input은 <sos>가 됩니다.
* 따라서 첫 번째 step에서 Decoder의 LSTM으로 진입하는 input은 <sos>, $z^1 = (h_{4}^{1}, c_{4}^{1}), z^2 = (h_{4}^{2}, c_{4}^{2})$ 입니다.
* 최종적으로는 fully-connected layer를 통해서 정해둔 임베딩 크기에 맞게 prediction 벡터를 리턴합니다.
이제 전체 Seq2Seq 모델을 살펴봅시다.
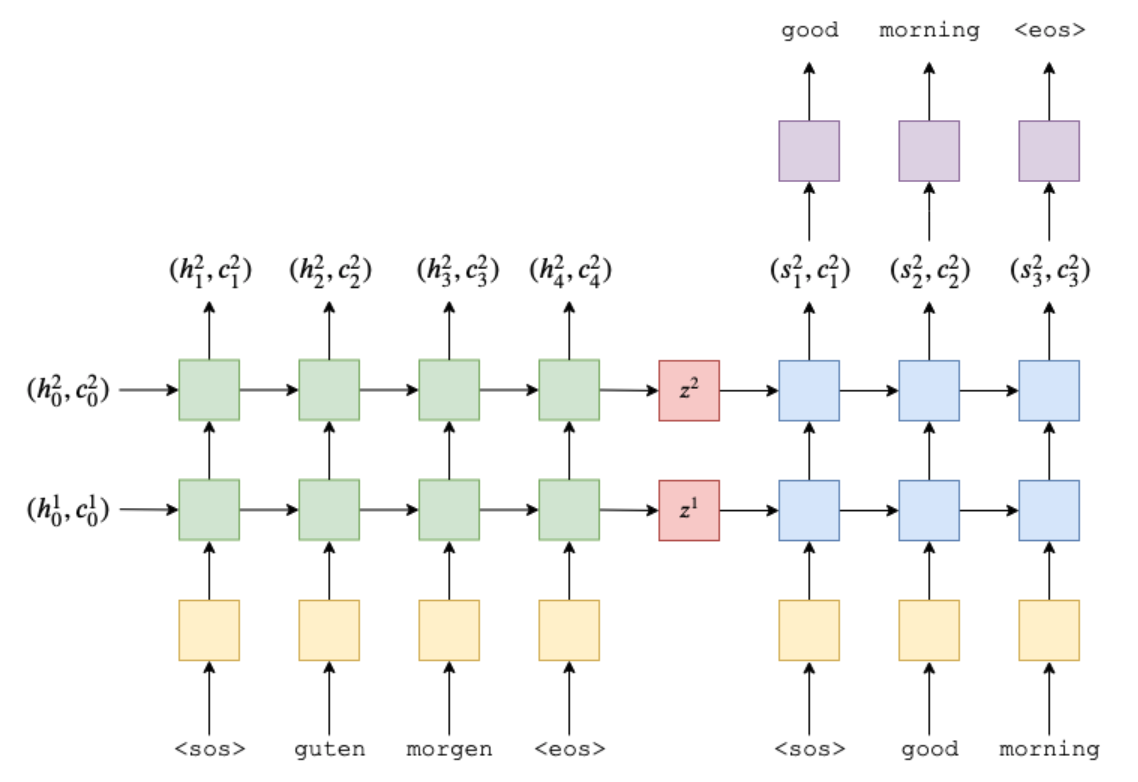
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
* forward 부분에서 input으로 받는 src, trg는 텐서로 매핑된 독일어 / 영어 문장입니다.
위에서 본 이 출력결과를 기억해봅시다. 배치사이즈가 뒤쪽 (1번째 index), 문장 길이가 앞쪽 (0번째 index) 에 있습니다.
* teacher_forcing_ratio는 다음 포스팅을 참조하시기 바랍니다.
* 최초 input은 trg[0, :] 로 선언되어 있는데, 이는 trg (영어 문장) 의 맨 앞부분인 <sos>를 받아오는 부분입니다.
* 앞서 선언한 decoder 함수에 input, hidden, cell을 넣고, hidden, cell을 업데이트하고 output을 가져옵니다.
* 최종적으로 예측 문장 (outputs) 이 나오게 됩니다.
이제 마지막으로 학습 코드를 살펴보고 마무리하겠습니다.
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
* stoi는 현재 단어 집합의 단어와 맵핑된 고유한 정수를 출력합니다. 여기서는 <pad>에 대한 정수값을 가져옵니다.
(source to index)
* nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX) 는 문장의 길이를 맞춰주기 위해 padding한 부분을 loss 계산에서 제외하는 것입니다.
* clip은 다음 포스팅을 참조하시기 바랍니다.
* iterator에는 앞서 선언한 train_iterator, valid_iterator, test_iterator가 들어갑니다.
제가 이해하고 싶어서 쓴 포스팅이라 약간 뒤죽박죽할 수 있을 것 같습니다.. 그래도 이쯤 보니 Seq2Seq가 실제로 어떻게 구현되는지 잘 파악된 것 같습니다. 모델 평가 metric에 대한 내용은 생략합니다.
감사합니다!



